Mixtral 8x7B model is now supported on xCloud for fine-tuning and inference!
The cloud for generative AI and LLMs
Sign up now to receive complimentary fine-tuning for your use-case
Accelerated Inference
Push the model inference to its limits with our hardware and software optimizations for each model. Supported by our robust, production-ready infrastructure featuring auto-scaling, fault recovery and monitoring.
Open Source Model APIs
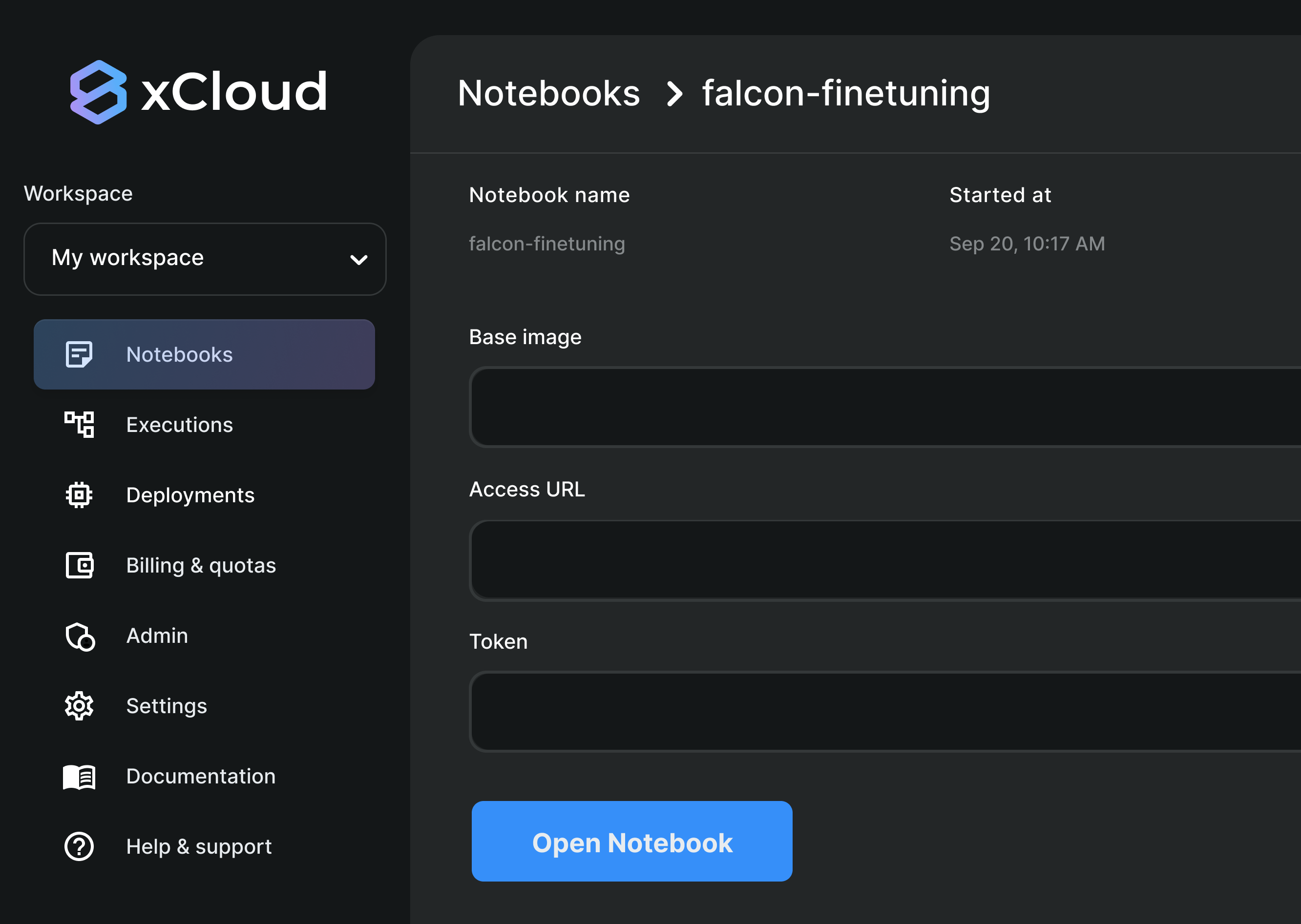
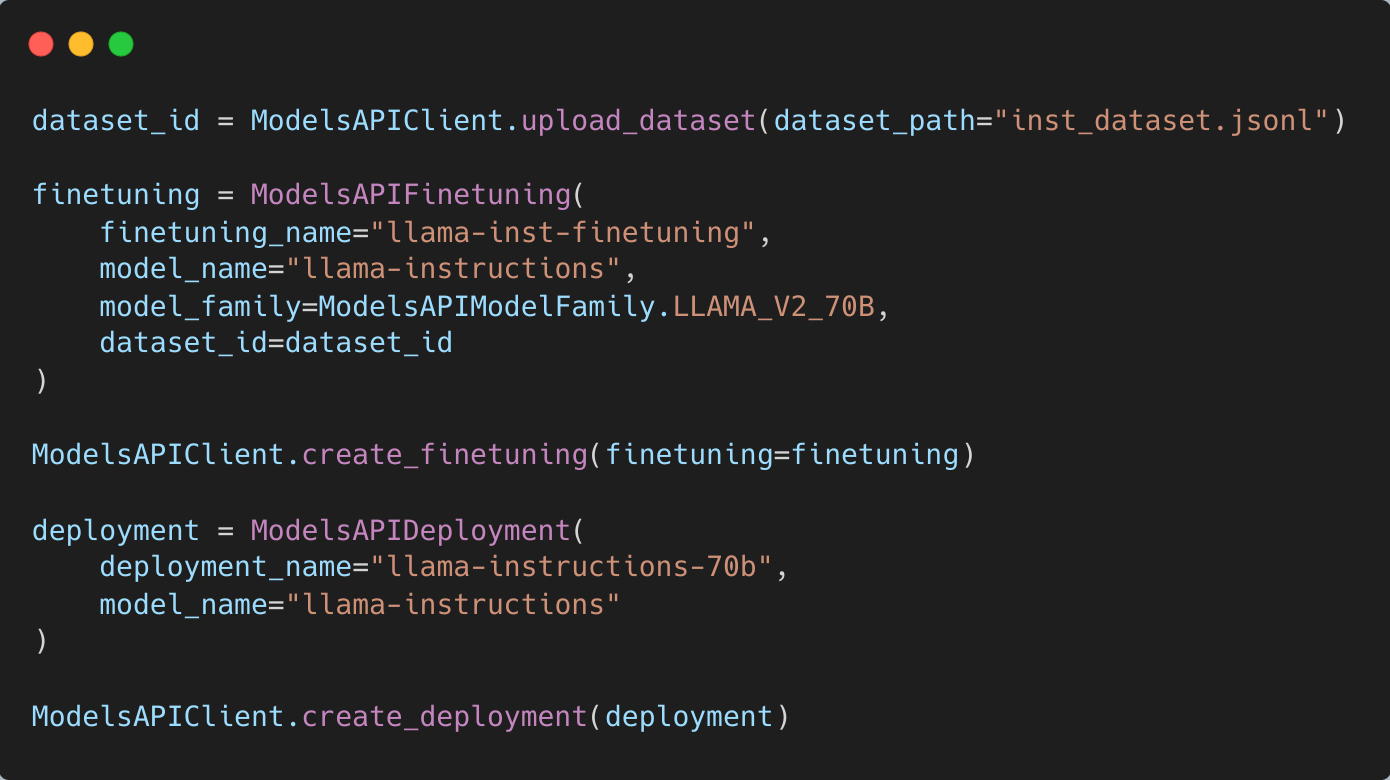
Effortlessly fine-tune and deploy open-source models like LLaMA-2-70B. Dedicate your focus to the data while we handle the heavy lifting—setting up the infrastructure, executing fine-tuning, and accelerating models
Compatible with OpenAI fine-tuning and supports popular models like LLaMA, Falcon, MPT, GPT and more.
Fine-tuning Flexibility
You have the freedom to customize every aspect of the fine-tuning of your LLMs. Connect your chosen data source, use your favorite framework, perform data transformations, write custom code.
xCloud seamlessly integrates into your existing workflow. Use it with the web dashboard, CLI or Python SDK.

Security and Privacy
Concerned about data privacy or looking to optimize costs with your own hardware?
Deploy xCloud on your preferred public cloud platform (AWS, Azure, or GCP) and rest assured that all your data and models will reside securely within your own VPC.
Unlock new capabilities
Build and deploy LLMs on any number of GPUs

HW Efficient Fine-tuning
Choose when the models are retrained to suit your business needs

Model Compression
Based on the application requirements, scale model sizes to achieve the best balance of quality, latency, and cost

Inference Optimization
Optimized inference stack to guarantee maximal throughput and minimal latency and cost

Enterprise Security
Your data is protected on a private cloud. Only authorized personnel can access your data and your AI
Testimonials
Stochastic's team have been a delight to work with and the xCloud product has been instrumental for us. We at NinjaTech AI have started to use xCloud right alongside AWS SageMaker, Google's Vertex and also Azure's machine learning studio. More specifically, after using xCloud's Automatic Acceleration technology, we were amazed by how it was able to automatically reduce our latency by quite a bit. Most importantly, the support team behind xCloud is superb and we'll continue to value our partnership with them.
Babak P.
CEO, NinjaTech AI Inc.